Foundations of Multi-Agent Path Finding
 Recent advances in robotics have laid the foundation for building large-scale multi-agent systems.
A great deal of research has focused on coordinating agents to fulfill different types of tasks.
We focus on one fundamental task -
to navigate teams of agents in a shared environment to their goal locations
without colliding with obstacles or other agents.
One well-studied abstract model for this problem is known as Multi-Agent Path Finding (MAPF).
It is defined on a general graph with given start and goal vertices for agents on this graph.
Each agent is allowed to wait at its current vertex or
move to an adjacent vertex from one discrete timestep to the next one.
We are asked to find a path for each agent such that no two agents are at the same vertex or
cross the same edge at any timestep (because this would result in a collision).
The objective is to minimize the sum of the arrival times of all agents.
Recent advances in robotics have laid the foundation for building large-scale multi-agent systems.
A great deal of research has focused on coordinating agents to fulfill different types of tasks.
We focus on one fundamental task -
to navigate teams of agents in a shared environment to their goal locations
without colliding with obstacles or other agents.
One well-studied abstract model for this problem is known as Multi-Agent Path Finding (MAPF).
It is defined on a general graph with given start and goal vertices for agents on this graph.
Each agent is allowed to wait at its current vertex or
move to an adjacent vertex from one discrete timestep to the next one.
We are asked to find a path for each agent such that no two agents are at the same vertex or
cross the same edge at any timestep (because this would result in a collision).
The objective is to minimize the sum of the arrival times of all agents.
We push the limits of MAPF solving by developing a variety of AI and optimization techniques to systematically reasoning about the collision-resolution space of the problem. Our optimal, bounded-suboptimal, and suboptimal MAPF algorithms can find solutions for a few hundred, a thousand, and a few thousand agents, respectively, within just a minute. The diagram below summarizes the empirical performance of some of our MAPF algorithms (solid lines) in comparison to some baseline MAPF algorithms (dashed lines). Success rate is the percentage of MAPF instances solved within a runtime limit of one minute.

Show more details of this empirical result.
The experiments were conducted on AWS EC2 instances “m4.large” with a runtime of 1 minute. The MAPF instances are the 25 instances in the ``random'' scenario on map ``Paris_1_256'' from the MAPF benchmark suite. The details of each MAPF algorithm are as follows.- A* is a vanilla A* algorithm that searches the joint-state space of the agents.
- CBS is from [Sharon et al AAAI'12]. Check out the code here.
- ICBS is CBS with the conflict prioritization technique from [Boyarski et al IJCAI'15]. Check out the code here.
- CBSH2-RTC is ICBS with the WDG heuristic from our IJCAI'19 paper, the RTC symmetry reasoning from our AIJ'21 paper, and the bypassing technique from [Boyarski et al IJCAI'15]. Check out the code here.
- EECBS is the most advanced version of EECBS from our AAAI'21 paper plus SIPPS from our AAAI'22 paper. Check out the code here.
- PBS is PBS from our AAAI'19 paper plus SIPPS from our AAAI'22 paper. Check out the code here.
- MAPF-LNS2 is from our AAAI'22 paper. Check out the code here.
Symmetry Reasoning for MAPF
 One of the reasons MAPF problems are so hard to solve is due to a phenomena called pairwise path symmetry, which occurs when two agents have many equivalent paths, all of which appear promising, but which are
pairwise incompatible because they result in a collision.
The symmetry arises commonly in practice and can produce an exponential explosion in the space of possible collision resolutions, leading to unacceptable runtimes for currently state-of-the-art MAPF algorithms that employ heuristic search, such as Conflict-based Search (CBS).
To break symmetries, we propose a variety of constraint-based reasoning techniques, to detect the symmetries as they arise and to efficiently eliminate, in a single branching step, all permutations of two currently assigned but pairwise incompatible paths.
One of the reasons MAPF problems are so hard to solve is due to a phenomena called pairwise path symmetry, which occurs when two agents have many equivalent paths, all of which appear promising, but which are
pairwise incompatible because they result in a collision.
The symmetry arises commonly in practice and can produce an exponential explosion in the space of possible collision resolutions, leading to unacceptable runtimes for currently state-of-the-art MAPF algorithms that employ heuristic search, such as Conflict-based Search (CBS).
To break symmetries, we propose a variety of constraint-based reasoning techniques, to detect the symmetries as they arise and to efficiently eliminate, in a single branching step, all permutations of two currently assigned but pairwise incompatible paths.
Highlights: The addition of the symmetry-reasoning techniques proposed in [3] can reduce the number of expanded nodes and runtime of the optimal algorithm CBS by up to 4 orders of magnitude and thus can handle up to 30 times more agents than possible before within one minute.
Relevant publications: [1] rectangle symmetry, [2] corridor and target symmetries, [3] generalized rectangle, target, and corridor symmetry reasoning, [4] automatic symmetry reasoning by mutex propagation (ICAPS’20 outstanding student paper), [5] mutex propagation for SAT-based MAPF, [6] improved mutex propagation, [7] symmetry reasoning for k-robust MAPF, [8] symmetry reasoning for agents of different shapes, [9] symmetry reasoning for train-like agents, [10] target symmetries used for MAPF with precedence constraints, and [11] symmetry reasoning with bounded-suboptimal CBS.
Heuristics for MAPF with Conflict-Based Search
 Conflict-Based Search (CBS) and its enhancements are among the strongest algorithms for MAPF.
However, existing variants of CBS do not use any heuristics that estimate future work.
Introducing admissible heuristics to guide the high-level search of CBS can significantly reduce the size of the CBS search tree and its runtime.
Introducing more informed but potentially inadmissible heuristics to guide the high-level search of bounded-suboptimal CBS with Explicit Estimation Search can further reduce the size of its search tree and its runtime.
Conflict-Based Search (CBS) and its enhancements are among the strongest algorithms for MAPF.
However, existing variants of CBS do not use any heuristics that estimate future work.
Introducing admissible heuristics to guide the high-level search of CBS can significantly reduce the size of the CBS search tree and its runtime.
Introducing more informed but potentially inadmissible heuristics to guide the high-level search of bounded-suboptimal CBS with Explicit Estimation Search can further reduce the size of its search tree and its runtime.
Highlights: The addition of the admissible heuristics proposed in [2] can reduce the number of expanded nodes and runtime of CBS by up to a factor of 50 and thus can handle up to 3 times more agents than possible before within one minute. The bounded-suboptimal MAPF algorithm proposed in [4] can find solutions that are provably at most 2% worse than optimal with 1,000 agents in one minute, while, on the same map, state-of-the-art optimal algorithms can handle at most 200 agents.
Relevant publications: [1] CG heuristic for CBS, [2] DG and WDG heuristics for CBS, [3] generalized WDG heuristic for CBS with large agents, and [3] inadmissible heuristic for bounded-suboptimal CBS.
Large Neighborhood Search for MAPF
 Sometimes, we are interested in a good solution but not necessarily a proof of how good the solution is.
Since providing optimality proofs is computationally expensive,
We develop Large Neighbor Search (LNS) algorithms
that repeatedly replan paths for subsets of agents via prioritized planning.
They give up optimality guarantees
but find near-optimal solutions for thousands of agents in practice,
solve 80% of the most challenging instances in the MAPF benchmark suite
(while previously the best suboptimal algorithms solve at most 65%), and
improve the solution quality by up to 36 times.
Sometimes, we are interested in a good solution but not necessarily a proof of how good the solution is.
Since providing optimality proofs is computationally expensive,
We develop Large Neighbor Search (LNS) algorithms
that repeatedly replan paths for subsets of agents via prioritized planning.
They give up optimality guarantees
but find near-optimal solutions for thousands of agents in practice,
solve 80% of the most challenging instances in the MAPF benchmark suite
(while previously the best suboptimal algorithms solve at most 65%), and
improve the solution quality by up to 36 times.
Relevant publications: [1] LNS for improving solution quality, [2] LNS for increasing success rates, [3] LNS for railway planning and replanning, [4] machine learning guided LNS for MAPF, and [5] LNS for multi-agent task and path planning.
Learning-Guided Planning
Machine Learning (ML) can complement the search algorithms and boost their performance by automatically discovering policies that are better than the hand-crafted ones and tailoring the randomized heuristics to the instances at hand. Examples include learning to generate priority orderings for prioritized planning and to select subsets of agents and determine the stopping criterion for LNS.
Relevant publications: [1] ML-guided LNS for MAPF, [2] ML-guided prioritized planning for MAPF, and [3] combining RL with LNS.
Learning individual policies for agents
An appealing alternative approach to using heuristic search methods is to use machine learning to directly learn a MAPF policy for each agent. Depending on implementation, this could theoretically be decentralized (e.g. each agent running its own policy and communicating with a small subset of neighboring agents), fast (just the time required for a neural network inference), and result in efficient paths.
Relevant publications

RAILGUN: A Unified Convolutional Policy for Multi-Agent Path Finding across Different Environments and Tasks.
Multi-Agent Path Finding (MAPF), which focuses on finding collision-free paths for multiple robots, is crucial for applications ranging from aerial swarms to warehouse automation. Solving MAPF is NP-hard so learning-based approaches for MAPF have gained attention, particularly those leveraging deep neural networks. Nonetheless, despite the community’s continued efforts, all learning-based MAPF planners still rely on decentralized planning due to variability in the number of agents and map sizes. We have developed the first centralized learning-based policy for MAPF problem called RAILGUN. RAILGUN is not an agent-based policy but a map-based policy. By leveraging a CNN-based architecture, RAILGUN can generalize across different maps and handle any number of agents. We collect trajectories from rule-based methods to train our model in a supervised way. In experiments, RAILGUN outperforms most baseline methods and demonstrates great zero-shot generalization capabilities on various tasks, maps and agent numbers that were not seen in the training dataset.
@inproceedings{ TangIROS25railgun,
author = "Yimin Tang and Xiao Xiong and Jingyi Xi and Jiaoyang Li and Erdem Bıyık and Sven Koenig",
title = "RAILGUN: A Unified Convolutional Policy for Multi-Agent Path Finding across Different Environments and Tasks",
booktitle = "Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)",
pages = "8645-8651",
year = "2025",
doi = "10.1109/IROS60139.2025.11247527",
}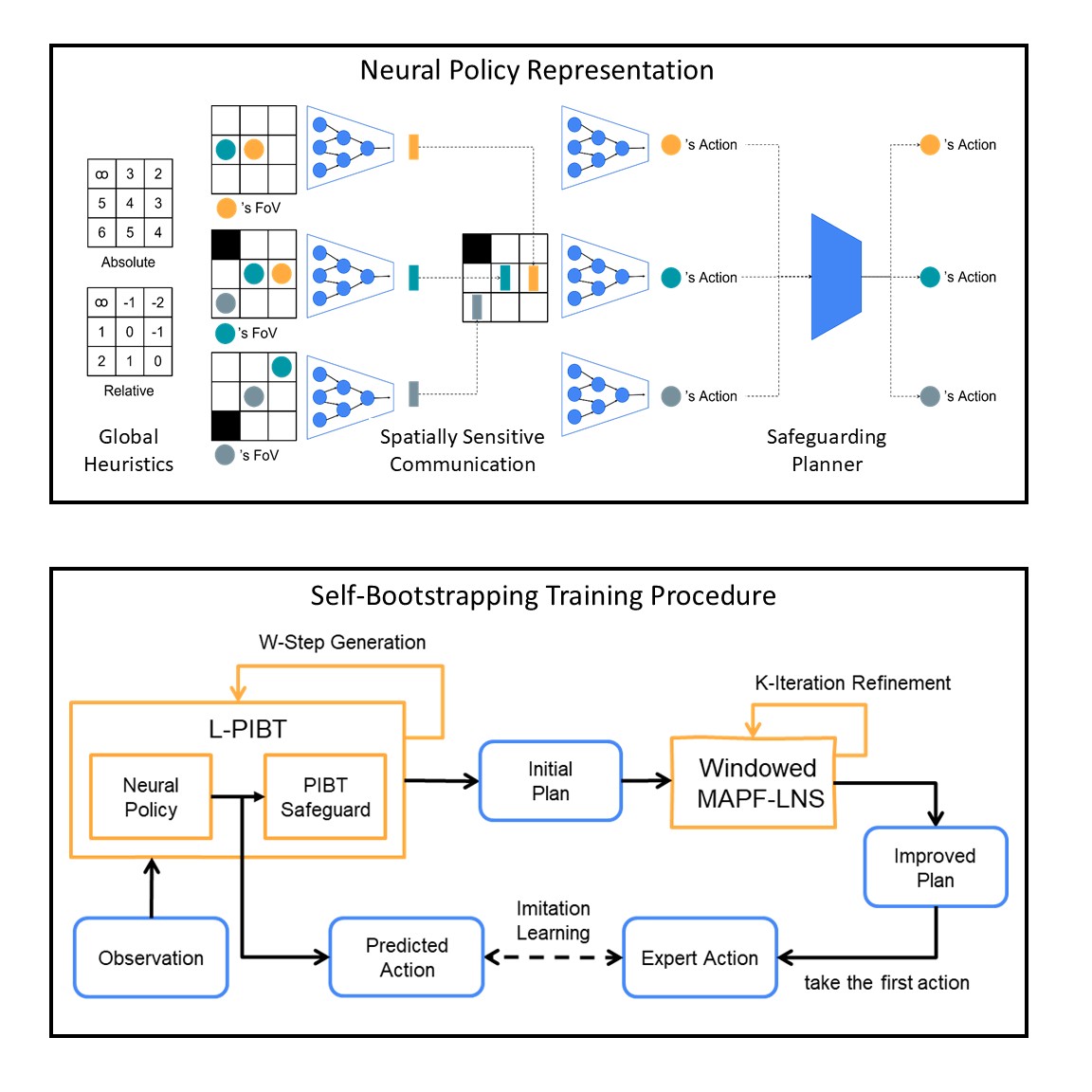
Deploying Ten Thousand Robots: Scalable Imitation Learning for Lifelong Multi-Agent Path Finding. (Best Paper on Multi-Robot Systems; Best Student Paper)
Lifelong Multi-Agent Path Finding (LMAPF) repeatedly finds collision-free paths for multiple agents that are continually assigned new goals when they reach current ones. Recently, this field has embraced learning-based methods, which reactively generate single-step actions based on individual local observations. However, it is still challenging for them to match the performance of the best search-based algorithms, especially in large-scale settings. This work proposes an imitation-learning-based LMAPF solver that introduces a novel communication module as well as systematic single-step collision resolution and global guidance techniques. Our proposed solver, Scalable Imitation Learning for LMAPF (SILLM), inherits the fast reasoning speed of learning-based methods and the high solution quality of search-based methods with the help of modern GPUs. Across six large-scale maps with up to 10,000 agents and varying obstacle structures, SILLM surpasses the best learning- and search-based baselines, achieving average throughput improvements of 137.7% and 16.0%, respectively. Furthermore, SILLM also beats the winning solution of the 2023 League of Robot Runners, an international LMAPF competition. Finally, we validated SILLM with 10 real robots and 100 virtual robots in a mock warehouse environment.
@inproceedings{ JiangICRA25,
author = "He Jiang and Yutong Wang and Rishi Veerapaneni and Tanishq Harish Duhan and Guillaume Adrien Sartoretti and Jiaoyang Li",
title = "Deploying Ten Thousand Robots: Scalable Imitation Learning for Lifelong Multi-Agent Path Finding",
booktitle = "Proceedings of the IEEE International Conference on Robotics and Automation (ICRA)",
pages = "7342-7348",
year = "2025",
doi = "10.1109/ICRA55743.2025.11127445",
}Work Smarter Not Harder: Simple Imitation Learning with CS-PIBT Outperforms Large Scale Imitation Learning for MAPF.
@inproceedings{ VeerapaneniICRA25,
author = "Rishi Veerapaneni and Arthur Jakobsson and Kevin Ren and Samuel Kim and Jiaoyang Li and Maxim Likhachev",
title = "Work Smarter Not Harder: Simple Imitation Learning with CS-PIBT Outperforms Large Scale Imitation Learning for MAPF",
booktitle = "Proceedings of the IEEE International Conference on Robotics and Automation (ICRA)",
pages = "10229-10236",
year = "2025",
doi = "10.1109/ICRA55743.2025.11128836",
}Improving Learnt Local MAPF Policies with Heuristic Search.
@inproceedings{ VeerapaneniICAPS24,
author = "Rishi Veerapaneni and Qian Wang and Kevin Ren and Arthur Jakobsson and Jiaoyang Li and Maxim Likhachev",
title = "Improving Learnt Local MAPF Policies with Heuristic Search",
booktitle = "Proceedings of the International Conference on Automated Planning and Scheduling (ICAPS)",
pages = "597-606",
year = "2024",
doi = "10.1609/icaps.v34i1.31522",
}